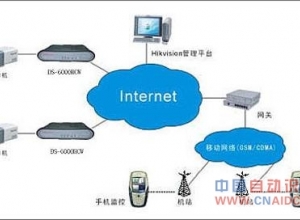
在城市轨道交通的监控中,智能视频分析技术曾风极一时,然而由于城市轨道交通的监控环境比较复杂,其不仅区域大、周界长、拥有多站台多出入及众多围栏等相关设备。这种复杂的环境给智能分析带来诸多困难,而作为当前新颖的TLD[跟踪-学习-检测"(Tracking-Learning-Detection)的缩写]视觉跟踪技术能够解决这些问题。
TLD跟踪系统最大的特点就在于能对锁定的目标进行不断的学习,以获取目标最新的外观特征,从而及时完善跟踪,以达到最佳的状态。也就是说,开始时只提供一帧静止的目标图像,但随着目标的不断运动,系统能持续不断地进行探测,获知目标在角度、距离、景深等方面的改变,并实时识别,经过一段时间的学习之后,目标就再也无法躲过。

TLD技术有三部分组成,即跟踪器、学习过程和检测器。TLD技术采用跟踪和检测相结合的策略,是一种自适应的、可靠的跟踪技术。TLD技术中,跟踪器和检测器并行运行,二者所产生的结果都参与学习过程,学习后的模型又反作用于跟踪器和检测器,对其进行实时更新,从而保证了即使在目标外观发生变化的情况下,也能够被持续跟踪。
跟踪器
TLD跟踪器采用重叠块跟踪策略,单块跟踪使用Lucas-Kanade光流法。TLD在跟踪前需要指定待跟踪的目标,由一个矩形框标出。最终整体目标的运动取所有局部块移动的中值,这种局部跟踪策略可以解决局部遮挡的问题。
学习过程
TLD的学习过程是建立在在线模型(onlinemodel)的基础上。在线模型是一个大小为15×15的图像块的集合,这些图像块来自跟踪器和检查器所得的结果,初始的在线模型为起始跟踪时指定的待跟踪的目标图像。
在线模型是一个动态模型,它随视频序列增长或减小。在线模型的发展有两个事件来驱动,分别为增长事件和修剪事件。由于在实际中,来自环境和目标本身等多因素的影响,使目标的外观不断发生变化,这使得由跟踪器预测产生的目标图像会包含更多其它感兴趣的因素。如果我们把跟踪轨迹上所有目标图像看成一个特征空间,那么随着视频序列的推进,由跟踪器所致的特征空间将不断增大,这就是所说的增长事件。为了防止增长事件带来的杂质(其他非目标图像)影响跟踪效果,采用了与之相对的修剪事件来平衡。修剪事件就是用来去除增长事件所致的杂质。由此,两事件的相互作用促使在线模型一直保持与当前的跟踪目标相一致。
由增长事件带来的特征空间的扩张来自于跟踪器,即从处于跟踪轨迹上的目标图像中选择合适的样本,并以此来更新在线模型。有三种选择策略,具体如下。
·与起始待跟踪目标图像相似的图像块,均被加入到在线模型;
·如果当前帧的跟踪目标图像与前一帧的相似,则将当前的跟踪结果图像加入到在线模型;
·计算跟踪轨迹上的目标图像到在线模型间的距离,选择具有特定模式的目标图像,即起初目标图像与在线模型的距离较小,随之距离逐渐增大,而后距离又恢复成较小状态。循环检验是否存在这种模式,并将该模式内的目标图像加入到在线模型。