2、改进的HDFS
2.1 HDFS存在的问题
因为Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Name.Node的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150byte左右的空间,所以,如果有100万个文件,每一个占据一个Block,就至少需要300MB内存;当扩展到数十亿时,对于当前的硬件水平来说就没法实现了,这样NameNode内存容量严重制约了集群的扩展。HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断从一个DataNode跳到另一个DataNode,处理大量小文件速度远远小于处理同等大小的大文件的速度,严重影响性能。其次,每一个小文件要占用一个Task,而Task启动将耗费大量时间甚至大部分时间都耗费在启动Task和释放Task上。还有一个问题就是,因为MapTask的数量是由Splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Map Task,线程管理开销将会增加作业时间。举个例子,处理10000M的文件,若每个Sprit为1M,那就会有10000个MapTasks,会有很大的线程开销;若每个Split为100M,则只有100个Map Tasks,每个Map Task将会有更多的事情做,而线程的管理开销也将减小很多。
2.2 HDFS改进
本文将多个小文件打包成一个归档文件,这样在减少NameNode内存使用的同时,仍然允许对文件进行透明的访问。当一个文件到达时,判断该文件是否属于小文件,如果是,则交给小文件处理模块处理,否则,交给通用文件处理模块处理。小文件处理模块的设计思想是,先将很多小文件合并成一个大文件,然后为这些小文件建立索引,以便进行快速存取和访问。小文件处理模块的流程如图3所示。
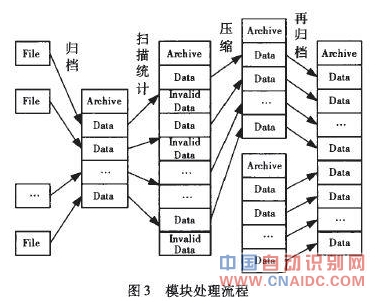
(1)小文件的归档管理主要由周期性执行的MapReduce任务完成。有以下几个处理流程:扫描元数据信息表,统计未归档的对象信息,包括在HDFS中的URI(Uniform Resource Identifier,通用资源标志符)、对象大小等;根据配置的归档文件大小限制,对统计所得的对象进行分组;将每个分组中的对象文件合并到一个归档文件中;更新相关对象元数据信息表中的数据位置描述项;删除旧的对象文件。
(2)归档文件的压缩主要有以下几个处理流程:扫描已删除对象表,统计无效对象信息;对于未归档的无效对象文件,直接删除;将已归档的无效对象按照归档文件分组;统计涉及的归档文件的空间利用率;统计利用率低于阈值的每个归档文件中所有有效对象信息;将归档文件中的有效对象数据合并到一个新的归档文件中;更新相关对象元数据信息表中的数据位置描述项;删除旧的归档文件。
(3)归档文件的再归档主要有以下几个处理流程:扫描归档文件列表,统计占用磁盘空间低于阈值的归档文件;根据归档文件大小配置参数,将统计所得归档文件分组;统计各分组归档文件涉及的对象;将每个分组中的归档文件合并到一个归档文件;将归档文件中的有效对象数据合并到一个新的归档文件中;更新相关对象元数据信息表中的数据位置描述项;删除旧的归档文件。
3、分布式文件系统对比
3.1实验环境
实验采用操作系统为CentOS5.4(Red Hat Enterprise Linux 4.1.2)系统,文件系统软件分别为Hadoop-0.19.2、Lustre-1.47、FastDFS-1.23、MogileFS-2.44、MooseFS.1.6.13,内存和I/O性能测试软件分别为Ubench和IOzone。使用8台PC搭建环境,硬件实验平台中电脑CPU为Intel Core 2.66GHz,Memory为2G/4G,240G硬盘,通过100Mbps交换机局域网连接。数据集为1亿个1kB,2000万个5kB,200万个50kB,100万个200kB,20万个1MB,2万个10MB,1千个100MB文件。
3.2性能对比
现有的各种各样分布式文件系统具有不同的性能特点,它们的功能也不尽相同。为了在具体领域更好地掌握和应用适合的分布式文件系统,本文从文件系统的几个主要方面进行了详细的比较分析。分析结果如表1所示。

从表1中,可以清楚地看到分布式文件系统各自的特点。在支持操作系统方面,各个系统都支持Linux操作系统,部分系统还支持Unix操作系统;在系统类型方面,HDFS等专用分布式文件系统具有较好的性能和较低的复杂度,而通用分布式文件系统在访问方式上提供标准API,还支持FUSE,可以管理分布式文件系统如同管理本地文件系统一样;在容错方面,Lustre在存储服务器上使用磁盘阵列,启用备用元数据管理服务器;HDFS和MooseFS在存储服务器上备份文件,在元数据日志服务器上备份日志,用于恢复元数据服务器;FastDFS和MogilesFS也在存储服务器上备份数据,在多个调度服务器上采用负载均衡策略。它们也有很多相似的地方,比如都支持在Linux操作系统上部署,都采用全局的命名空间,都有很好的可扩展性等。
在元数据管理节点方面,FastDFS和MogileFS有多个调度服务器,并发访问能力比较突出,Lustre有两个元数据管理服务器,www.cnaidc.com 其中一个是活动服务器宕机后自动启动的后备服务器,有效地解决了单点依赖问题,而HDFS、MooseFS和改进HDFS只有一个元数据管理服务器,存在单点依赖问题,而且元数据都保存在内存中,当文件数量超过一定范围时,还会遇到内存瓶颈;在元数据占用内存方面,HDFS每个文件元数据占用内存大约150~200Byte之间,MooseFS每个元数据大约300Byte,而且随着文件数量增加内存占用也越大;Lustre元数据只占用4Byte左右,当文件数量超过2000万,内存占用也随之增大;改进HDFS内存占用与文件数量关系不大,随着文件数据增大稍微增长,当文件数量达到6000万,内存性能与Lustre持平。元数据内存占用情况如图4所示。
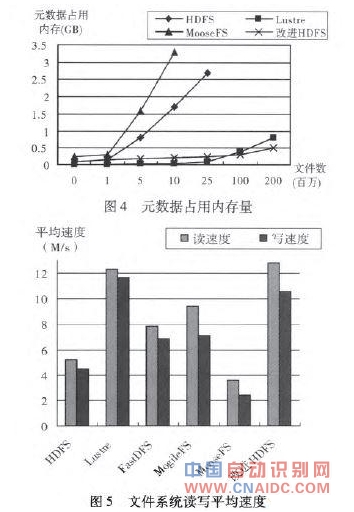
在文件存取方面,HDFS和MogileFS通常用来存储静态大文件,而MooseFS和改进HDFS可以存储各种文件,存储的文件一般不需要修改,只提供下载服务;FastDFS一般用于存储音频、视频和文档等,文件比较小,所以不分块存储文件,以文件为单位来存储;而Lustre以分条的方式存储文件,主要存储密集型数据,进行高性能计算;相对于HDFS,改进的HDFS平均读写速度增加了一倍左右,读速度略高于Lustre,但写速度略逊于Lustre。文件系统读写平均速度如图5所示。
4、结束语
云存储是近年来被广泛应用的新技术,可以广泛应用于一些重要的领域,如气象领域、视频分享网站等,因此分布式文件系统也引来了更多的关注,在学术界和工业界都有很多的分布式文件系统。如何选择合适的分布式文件系统是一个大问题,本文在架构、访问方式、文件存储方式等方面进行了详细的对比,并对HDFS在I/O性能方面进行了改进,根据这些信息,用户可以合理地选择分布式文件系统。虽然各个分布式文件系统有各自的优势和特点,但还有一些亟待解决的问题,下一步将进一步解决单元数据管理服务器依赖问题、多调度服务器负载均衡问题、系统容错机制和并发读写等。