








ЁЁЁЁЫцзХЙњУёОМУЕФИпЫйЗЂеЙКЭГЧЪаЛЏНјГЬЕФМгПьЃЌЮвЙњЕФЛњЖЏГЕгЕгаСПМАЕРТЗНЛЭЈСїСПМБОчдіМгЁЃШевцдіГЄЕФНЛЭЈашЧѓгыГЧЪаЕРТЗЛљДЁЩшЪЉжЎМфЕФУЌЖмвбГЩЮЊФПЧАГЧЪаНЛЭЈЕФжївЊУЌЖмЃЌгЩДЫЕМжТНЛЭЈгЕМЗКЭЖТШћЦЕЦЕЗЂЩњЁЃНЛЭЈгЕЖТбЯжигАЯьСЫШЫУЧЕФШеГЃГіааЛюЖЏЃЌжЦдМзХГЧЪаОМУЕФЗЂеЙЁЃвђДЫЃЌЖдНЛЭЈЪТМўгШЦфЪЧНЛЭЈгЕЖТЕФЪЖБ№ОЭЯдЕУгШЦфживЊЃЌЯрЙибаОПЙЄзївВЕУЕНСЫвЛаЉбЇепЕФжиЪгЁЃИпРіУЗЕШКЭбюзцдЊЕШНЋОлРрЫуЗЈгІгУЕФНЛЭЈзДЬЌХаБ№жаЃЌдквЛЖЈГЬЖШЩЯПЩвдЪЕЯжНЛЭЈзДЬЌЗжРрЁЃЕЋгЩгкЫуЗЈУЛгаЖдШБЪЇЪ§ОнКЭДэЮѓЪ§ОнНјааДІРэЃЌЛсдьГЩОлРржааФЕФЦЋРыЃЌЖдзюжеХаБ№НсЙћгАЯьНЯДѓЁЃЮзЭўЬїЕШКЭФєХхСжЕШРћгУЩёОЭјТчЕФздбЇЯАКЭЗЧЯпадФтКЯФмСІЖдНЛЭЈзДЬЌНјааХаБ№ЃЌгЩгкбЕСЗбљБОЕФбЁШЁЖдЭјТчФЃаЭбЕСЗНсЙћгАЯьНЯДѓЃЌЕМжТФЃаЭЕФЪЪгУадБфВюЁЃЮФЯзеыЖдНЛЭЈзДЬЌЕФФЃК§адЃЌЭЈЙ§НЈСЂФЃК§ЙиЯЕНјааНЛЭЈзДЬЌХаБ№ЃЌЕЋДцдкСЅЪєЖШКЏЪ§ЕФбЁдёвдМАЙцдђЕФУЖОйЕШЮЪЬтЁЃ
ЁЁЁЁАщЫцМЦЫуЛњЁЂЭЈаХЕШММЪѕЕФЗЂеЙЃЌНЛЭЈгЕЖТздЖЏЪЖБ№ЃЈAutomatic Congestion IdentificationЃЌACIЃЉММЪѕГЩЮЊНтОіНЛЭЈгЕЖТЮЪЬтЕФаТЫМТЗЁЃACIММЪѕЕФКЫаФЙІФмЪЧРћгУИїжжМьВтЩшБИЪЕЪБВЩМЏНЛЭЈЪ§ОнЃЌВЂвРОнЯрЙиРэТлгыЗНЗЈПьЫйЪЖБ№ЕУЕННЛЭЈгЕЖТЗЂЩњЕФЪБМфЁЂЕиЕуЕШаХЯЂЃЌДгЖјЮЊНЛЭЈЙмРэВПУХЬсЙЉаХЯЂВЮПМЁЃЯжгаНЛЭЈзДЬЌЪЖБ№ММЪѕЕФЪ§ОнРДдДжївЊАќРЈЪгЦЕМрПиЁЂЖЈЕуЯпШІМьВтКЭИЁЖЏГЕЪ§ОнВЩМЏЕШЁЃгЩгкЪгЦЕМрПиЩшБИЕФЪгвАЗЖЮЇгаЯоЭЌЪБЙЄзїШЫдБРЭЖЏЧПЖШДѓЁЂЖЈЕуЯпШІзАжУЕФЕРТЗИВИЧЗЖЮЇНЯаЁЧвЯпШІШнвзЫ№ЛЕЁЂGPSИЁЖЏГЕЕФЪ§СПЭљЭљВЛзуЕШжюЖрЮЪЬтЃЌЕМжТНЛЭЈзДЬЌХаБ№ВЛЙЛОЋШЗЁЃЫцзХЯрЙиММЪѕЕФЭъЩЦЃЌГЕХЦВЖЛёТЪгыЪЖБ№ТЪЕФЯджјЬсИпЃЌЛљгкГЕХЦЪЖБ№Ъ§ОнЕФНЛЭЈаХЯЂВЩМЏММЪѕгІгУЖјЩњЁЃЯрБШЦфЫћНЛЭЈаХЯЂВЩМЏММЪѕЃЌЛљгкГЕХЦЪЖБ№Ъ§ОнЕФНЛЭЈаХЯЂВЩМЏММЪѕОпгаЙЄзїСЌајадЧПЁЂЪ§ОнОЋШЗЖШИпЁЂМьВтбљБОСПДѓЕШгХЕуЁЃНЊЙ№боЕШЩшМЦСЫЛљгкГЕХЦЪЖБ№Ъ§ОнЕФЕЅГЕааГЬЫйЖШВЩМЏЗНЗЈКЭЧјМфЦНОљааГЬЫйЖШВЩМЏЗНЗЈЃЌЖдНЛЭЈгЕЖТЪЖБ№ЗНЗЈНјааСЫбаОПЁЃЕЋдкНјаавьГЃЪ§ОнДІРэЪБЃЌВЩгУЕФЪЧЦНОљжЕЗНЗЈЃЌетЖдгкВЛЭЌНЛЭЈЪБЖЮЖјбдЃЌЪ§ОнДІРэЮѓВюБШНЯДѓЃЌФбвдБЃжЄЪ§ОнДІРэЕФзМШЗадЁЃ
ЁЁЁЁеыЖдЩЯЪіНЛЭЈзДЬЌХаБ№ЗНЗЈДцдкЕФЮЪЬтЃЌБОЮФЩшМЦСЫвЛжжЛљгкГЕХЦЪЖБ№Ъ§ОнЕФНЛЭЈзДЬЌХаБ№ЗНЗЈЃЌЭЈЙ§вьГЃЪ§ОнЬоГ§ЁЂШБЪЇЪ§ОнВЙГЅДІРэБЃжЄСЫЪ§ОнЕФзМШЗадЁЃИљОнбљБОСПКЭНЛЭЈЪБЖЮЖдТУааЪБМфНјааМЦЫуЃЌБЃжЄСЫТУааЪБМфМЦЫуЕФКЯРэадЁЃФГТЗЖЮЪЕВтЪ§ОнМЦЫуНсЙћЃЌбщжЄСЫИУЗНЗЈЕФгааЇадКЭЪЕгУадЁЃ
ЁЁЁЁ2 ГЕХЦЪ§ОнВЩМЏЗНЗЈМђНщ
ЁЁЁЁ2.1 ГЕХЦЪЖБ№ММЪѕЖЈвх
ЁЁЁЁГЕХЦЪЖБ№ММЪѕ(Vehicle License Plate RecognitionЃЌVLPR) ЪЧжИФмЙЛМьВтЕНЪмМрПиТЗУцЕФГЕСОВЂздЖЏЬсШЁГЕСОХЦееаХЯЂЃЈКЌККзжзжЗћЁЂгЂЮФзжФИЁЂАЂРВЎЪ§зжМАКХХЦбеЩЋЃЉНјааДІРэЕФММЪѕЁЃГЕХЦЪЖБ№ЪЧЯжДњжЧФмНЛЭЈЯЕЭГжаЕФживЊзщГЩВПЗжжЎвЛЃЌгІгУЪЎЗжЙуЗКЁЃЫќвдЪ§зжЭМЯёДІРэЁЂФЃЪНЪЖБ№ЁЂМЦЫуЛњЪгОѕЕШММЪѕЮЊЛљДЁЃЌЖдЩуЯёЛњЫљХФЩуЕФГЕСОЭМЯёЛђепЪгЦЕађСаНјааЗжЮіЃЌЕУЕНУПвЛСОЦћГЕЮЈвЛЕФГЕХЦКХТыЃЌДгЖјЭъГЩЪЖБ№Й§ГЬЁЃ
ЁЁЁЁ2.2 ГЕХЦЪ§ОнВЩМЏЙцдђ
ЁЁЁЁАВзАГЕХЦЪЖБ№ЩшБИгкЕРТЗЕФЦ№жЙЕуЃЌЪЖЖСЫљгаЭЈЙ§ГЕСОВЂМЧТМГЕХЦКХТыКЭЪБМфЃЌНЋЪ§ОнДЋЫЭжСЪ§ОнДІРэЯЕЭГЃЌМЦЫуГіГЕСОЕФЦНОљТУааЪБМфЁЃЦфжаГЕХЦЪЖБ№ЩшБИАќРЈЕчзгОЏВьЁЂПЈПкЁЂЕчзгГЕХЦЕШЁЃ
ЁЁЁЁВЩМЏГЕХЦжжРржЛЯогкаЁаЭГЕГЕХЦЃЌВЛВЩМЏФІЭаГЕЁЂЙЋНЛГЕЕШГЕСОЕФГЕХЦЁЃ
ЁЁЁЁВЩМЏЪБМфЗЖЮЇЮЊЯТгЮТЗПкЮЊЕБЧАЪБМфЖЮ ЃЈвЛАуЩшжУЮЊ5ЗжжгЃЉЕФЙ§ГЕгыЩЯгЮТЗПкЕБЧАЪБМфЖЮ ЃЈвЛАуЩшжУЮЊ30ЗжжгЃЉЕФЙ§ГЕЁЃ
ЁЁЁЁВЩМЏЕиЕуЗЖЮЇЮЊЩЯгЮТЗПкбЁШЁЕФЗНЯђгыГЕЕРвдАДе§ГЃНЛЭЈЯАЙпНјШыЭГМЦТЗЖЮЮЊддђЃЌЦСБЮдкЗЧе§ГЃНЛЭЈЯАЙпЯТНјШыТЗЖЮЕФГЕЕРгыТЗПкЗНЯђЁЃвде§НЛЪЎзжТЗПкЮЊР§ЃЌВЩгУЯТСаЕиЕуЕФЙ§ГЕЪ§ОнЃК
ЁЁЁЁЃЈ1ЃЉЖдЯђЕРТЗЪЙгУжБааГЕЕРЕФЙ§ГЕЪ§ОнЃЛ
ЁЁЁЁЃЈ2ЃЉзѓзЊНјШыЭГМЦТЗЖЮЕФЩЯгЮТЗПкбЁШЁЕРТЗБъЯпжИУїзѓзЊГЕЕРЕФЙ§ГЕЪ§ОнЃЛ
ЁЁЁЁЃЈ3ЃЉгвзЊНјШыЭГМЦТЗЖЮЕФЩЯгЮТЗПкШчЙћКЌгагвзЊЕЦПиЃЌдђбЁШЁгвзЊГЕЕРЕФЙ§ГЕЪ§ОнЁЃ
ЁЁЁЁЯТгЮТЗПквджБааГЕЕРЮЊжїбЁШЁЙ§ГЕЪ§ОнЃЈгагвзЊЕЦПиЕФТЗПкПЩвдВЩгУгвзЊГЕЕРЕФЙ§ГЕЪ§ОнЃЉЁЃдкФГаЉЬиЪтТЗЖЮЯТЃЌФкВрГЕЕРвђЪмзѓзЊЃЈЕєЭЗЃЉаХКХЕФПижЦЃЌЭљЭљЛсВњЩњХХЖгЯжЯѓЃЌИУГЕЕРЕФТУааЪБМфашЕЅЖРЭГМЦЃЌБмУтЖджБааГЕЕРЕФВЩбљЪ§ОндьГЩИЩШХЁЃ
ЁЁЁЁ3 ЛљгкГЕХЦЪЖБ№Ъ§ОнЕФНЛЭЈзДЬЌХаБ№ЗНЗЈ
ЁЁЁЁ3.1 ГЕХЦаХЯЂДІРэ
ЁЁЁЁГЕХЦаХЯЂДІРэЕФгВМўвЛАуАќРЈДЅЗЂЩшБИЃЈМрВтГЕСОЪЧЗёНјШыЪгвАЃЉЁЂЩуЯёЩшБИЁЂееУїЩшБИЁЂЭМЯёВЩМЏЩшБИЁЂЪЖБ№ГЕХЦКХТыЕФДІРэЛњЃЈШчМЦЫуЛњЃЉЕШЃЌШэМўКЫаФАќРЈГЕХЦЖЈЮЛЫуЗЈЁЂГЕХЦзжЗћЗжИюЫуЗЈКЭЙтбЇзжЗћЪЖБ№ЫуЗЈЕШЁЃЕБГЕСОМьВтВПЗжМьВтЕНГЕСОЕНДяЪБДЅЗЂЭМЯёВЩМЏЕЅдЊЃЌВЩМЏЕБЧАЕФЪгЦЕЭМЯёЁЃГЕХЦЪЖБ№ЕЅдЊЖдЭМЯёНјааДІРэЃЌЖЈЮЛГіХЦееЮЛжУЃЌдйНЋХЦеежаЕФзжЗћЗжИюГіРДНјааЪЖБ№ЃЌШЛКѓзщГЩХЦееКХТыЪфГіЁЃОпЬхДІРэЙ§ГЬШчЯТЃК
ЁЁЁЁЃЈ1ЃЉГЕХЦаХЯЂБъзМЛЏДІРэ
ЁЁЁЁБъзМЛЏДІРэжївЊЪЧЮЊСЫБЃжЄЪ§ОнИёЪНЕФвЛжТадКЭгУЛЇаХЯЂЕФБЃУмадЃЌВЩгУЖрЮЛБрТыЕФЗНЪНВЂНјааМгУмДІРэКѓдйДцШыЪ§ОнПтжаЁЃ
ЁЁЁЁЃЈ2ЃЉГЕХЦаХЯЂдЄДІРэ
ЁЁЁЁЧјМфТУааЪБМфЭЈЙ§ГЕХЦЪЖБ№ЩшБИЛёЕУЕЅГЕЭЈЙ§СНИіЖЯУцЕФЪБПЬЃЌМЦЫуЙЋЪНЮЊЃК

ЁЁЁЁЛЛЫуГЕСОiдкИУТЗЖЮЕФааГЬЫйЖШЮЊЃК

ЁЁЁЁ3.2 вьГЃЪ§ОнЬоГ§
ЁЁЁЁгЩгкгВМўЙЪеЯЁЂЛЗОГБфЛЏЕШвђЫиЕФгАЯьЃЌГЕХЦЪ§ОнжаГЃГЃЛсГіЯжвьГЃЪ§ОнЁЃШчЙћАбетаЉЪ§ОнКЭе§ГЃЪ§ОнЗХдквЛЦ№НјааЭГМЦЃЌЛсЖдМЦЫуНсЙћВњЩњВЛРћгАЯьЃЌЫљвддкТУааЪБМфМЦЫуЧАЃЌашвЊЬоГ§етаЉвьГЃЪ§ОнЁЃФПЧАвьГЃЪ§ОнЕФХаБ№гыЬоГ§жївЊгаЮяРэХаБ№ЗЈКЭЭГМЦХаБ№ЗЈСНжжЗНЗЈЁЃЫљЮНЮяРэХаБ№ЗЈОЭЪЧИљОнШЫУЧЖдПЭЙлЪТЮявбгаЕФШЯЪЖЃЌХаБ№гЩгкЭтНчИЩШХЁЂШЫЮЊЮѓВюЕШдвђдьГЩЪЕВтЪ§ОнЦЋРые§ГЃНсЙћЃЌдкЪЕбщЙ§ГЬжаЫцЪБХаЖЯЃЌЫцЪБЬоГ§ЁЃЭГМЦХаБ№ЗЈЪЧИјЖЈвЛИіжУаХИХТЪЃЌВЂШЗЖЈвЛИіжУаХЯоЃЌЗВГЌЙ§ДЫЯоЕФЮѓВюЃЌОЭШЯЮЊЫќВЛЪєгкЫцЛњЮѓВюЗЖЮЇЃЌНЋЦфЪгЮЊвьГЃЪ§ОнЬоГ§ЁЃБОЮФзлКЯетСНжжЗНЗЈЖдвьГЃЪ§ОнНјааХаБ№КЭЬоГ§ЁЃОпЬхЙ§ГЬШчЯТЃК
ЁЁЁЁе§ГЃааЪЛГЕСОЕФЫйЖШЧјМфгІИУЗћКЯвЛАуЕФааГЬЫйЖШЧјМфЗЖЮЇ[a km/h, b km/h]ЃЌАбааГЬЫйЖШзЊЛЛГЩТУааЪБМфПЩаХЧјМфЮЊ[L/b km/h, L/a km/h]ЁЃ
ЁЁЁЁЃЈ1ЃЉШєТУааЪБМфаЁгкL/ b km/hЪБЃЌЧвИУРрЪ§ОндкзмбљБОСПжаеМБШЕЭгк20%ЪБЃЌдђЪгЮЊвьГЃЪ§ОнгшвдЧхГ§ЁЃ
ЁЁЁЁЃЈ2ЃЉШєТУааЪБМфДѓгкL/a km/hЪБЃЌЧвИУРрЪ§ОндкзмбљБОСПжаеМБШЕЭгк20%ЪБЃЌдђЪгЮЊвьГЃЪ§ОнгшвдЧхГ§ЁЃ
ЁЁЁЁЭЈЙ§ГЌЯоЪ§ОнЬоГ§ЃЌПЩвдБШНЯКУЕФЦСБЮЕєЙ§ДѓЛђЙ§аЁЕФвьГЃЪ§ОнЃЌЮЊЯТУцЕФЭГМЦЗжЮіЬсЙЉИпжЪСПЕФЛљДЁЪ§ОнЁЃ
ЁЁЁЁ3.3 ТУааЪБМфЭГМЦЗНАИ
ЁЁЁЁЭГМЦЗНАИПМТЧНЛЭЈСїЕФИпЗхЦкЁЂЦНЗхЦкЁЂЕЭЗхЦкШ§жжЧщПіЃЌНсКЯЦЅХфЩЯЕФГЕХЦЪ§СПдкОЙ§вьГЃЪ§ОнЬоГ§КѓАДееДѓбљБОСП[f5,+∞]ЁЂаЁбљБОСП[f3,f4]ЁЂЙТСЂЕу[f1,f2]ЃЈf1-f5ЮЊбљБОСПЗЇжЕЃЉШ§жжЧщПіНјааТУааЪБМфМЦЫуЁЃдкФГаЉЬиЪтГЁКЯЯТвЊгУЩЯЯТгЮЕФЙ§ГЕСПЁЂЩЯжмЦкТЗПізДЬЌРДИЈжњЭГМЦЁЃ
ЁЁЁЁ1ЁЂДѓбљБОСПЭГМЦЗНАИ
ЁЁЁЁОнЭГМЦТУааЪБМфЪ§ОнЗћКЯе§ЬЌЗжВМЙцТЩЃЌРћгУ3σзМдђЃЌЖдТУааЪБМфЪ§ОнДІРэЃЌМЦЫуЙЋЪНЮЊЃК

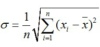 ЁЃ
ЁЃЁЁЁЁХХГ§аЁИХТЪЪ§ОнВЂНЋЙ§ТЫКѓЕФЪ§ОнЧѓЫуЪѕЦНОљжЕЃЌЫљЕУНсЙћзїЮЊБОжмЦкЕФТУааЪБМф T1ЁЃЭГМЦЕФбљБОСПжааЁгкТУааЪБМфT1ЕФЫљгабљБОЪ§ОнЕФЦНОљжЕзїЮЊЧјМфе§ГЃааЪЛЕФТУааЪБМфЁЃ
ЁЁЁЁ2ЁЂаЁбљБОСПЭГМЦЗНАИ
ЁЁЁЁРћгУ3σзМдђЃЌЖдТУааЪБМфЪ§ОнНјааМЦЫуЃЌХХГ§аЁИХТЪЪ§ОнВЂНЋЗћКЯ3σЕФбљБОЪ§ОнЧѓЫуЪ§ЦНОљжЕзїЮЊБОжмЦкЕФТУааЪБМф T1ЃЌЭЌЪБзїЮЊЭЦЫуТЗПіЕФТУааЪБМфЃЌМЦЫуЙЋЪНЭЌЪНЃЈ1ЃЉЁЃ
ЁЁЁЁ3ЁЂЙТСЂЕуЭГМЦЗНАИ
ЁЁЁЁЃЈ1ЃЉИпЗхЪБЖЮГіЯжЪ§ОнСПКмаЁЃЌХаЖЈЮЊгЩгЕЖТдьГЩЃЌжЛЗЂВМТЗЖЮгЕЖТзДЬЌаХЯЂЃЛ
ЁЁЁЁЃЈ2ЃЉЦНЗхЪБЖЮГіЯжЪ§ОнСПКмаЁЃЌЧвЩЯжмЦкТЗПіЮЊГЉЭЈЧщПіЪБЃЌВЩгУЧАжмЦкЕФЪ§ОнНјааЛжИДЃЌЛжИДЦкЯоЮЊ3жмЦкЁЃЕк3жмЦкШчЙћЛЙЪЧЙТСЂжЕЪБЃЌЗЂВМЩЯжмЭЌжмЦкРњЪЗЪ§ОнЁЃ
ЁЁЁЁЃЈ3ЃЉЕЭЗхЪБЖЮГіЯжЪ§ОнСПКмаЁЃЌВЂЧвЩЯвЛИіжмЦкЕФТЗПіЮЊГЉЭЈЧщПіЪБЃЌНЋЗЂВМздгЩСїЫйЖдгІЕФТУааЪБМфЃЛЗёдђХаЖЯЮЊГіЯжНЛЭЈЖТШћдьГЩЪ§ОнШБЪЇЃЌВЩгУЧАжмЦкЕФЪ§ОнНјааЛжИДЃЌЮФеТРДдД:жаЙњздЖЏЪЖБ№Эјwww.cnaidc.com ШБЪЇЪ§ОнГЌЙ§3жмЦкКѓНЋЭГМЦЧА15ЗжжгЕФЙ§ГЕЪ§ОнзїЮЊВЙГЅЪ§ОнЁЃ
ЁЁЁЁСэЭтЃЌЗЧЕЭЗхЪБЖЮЕБМьВтЕНЩЯЯТгЮЙ§ГЕСПЮЊ0ЪБЃЌХаЖЯЮЊЩшБИвьГЃЃЌЗЂВМЩЯжмЭЌжмЦкРњЪЗЪ§ОнЁЃЕЭЗхЪБЖЮНјааЪ§ОнЛжИДЃЌЛжИДЦкЯоЮЊ3жмЦкЁЃ3жмЦкКѓВЩгУздгЩСїЫйЖШЃЈвРОнБОТЗЖЮвЛжмЕФРњЪЗЪ§ОнЕУГіЕФОбщжЕЃЉЖдгІЕФТЗЖЮТУааЪБМфЃЌТЗЖЮНЛЭЈгЕЖТзДЬЌЮЊГЉЭЈЁЃ
ЁЁЁЁ3.4 ШБЪЇЪ§ОнВЙГЅ
ЁЁЁЁгЩгкжжжждвђЃЈШчЪЉЙЄЫ№ЛЕЁЂЯпТЗЙЪеЯЁЂДІРэДэЮѓЕШЃЉЃЌетаЉГЕХЦаХЯЂЪ§ОнжаДцдкШБЪЇжЕЯжЯѓЃЌЖдНЛЭЈСїСПЪ§ОнЕФЗжЮіКЭЩюВуДЮЕФЪ§ОнЭкОђДјРДВЛРћгАЯьЃЌвђДЫашвЊЖдетаЉШБЪЇжЕНјааДІРэЁЃ
ЁЁЁЁЗЧЕЭЗхЪБЖЮЕБМьВтЕНЩЯЯТгЮЙ§ГЕСПаЁгк5ЪБЃЌХаЖЯЮЊЩшБИвьГЃЁЂТЗПкЖТШћЕШЧщПіЕМжТПЩгУбљБОСПНЯЩйЃЌДЫЧщПіХаЖЈЮЊЪ§ОнШБЪЇЁЃЖдгкСЌајЩйгкШ§ИіВЩбљМфИєЕФЪ§ОнШБЪЇЃЌПЩвдЭЈЙ§ЧАвЛЖЮЪБМфФкЕФЪ§ОнНјааЛжИДЃЌОпЬхМЦЫуЙЋЪНЮЊЃК
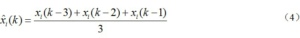
ЁЁЁЁРњЪЗЪ§ОнЪЧИљОнЖрЬьЪ§ОнЕФЦНЛЌжЕЕУЕНЕФЃЌЭЈЙ§етвЛЗНЗЈФмЙЛЕУЕНШЮвтЬьЕФРњЪЗЪ§ОнЃЌЫќОпгаБфЛЏЦНЮШЁЂВЈЖЏадаЁЕФЬиЕуЁЃНЋЦфБЃДцЯТРДзїЮЊНёКѓЪ§ОнЭГМЦКЭЗжЮіЕФЛљДЁЪ§ОнЃЌФмЙЛКмКУЕФУшЪіРњЪЗНЛЭЈзДЬЌБфЛЏЬиадЁЃОпЬхМЦЫуЙЋЪНШчЯТЃК
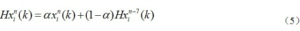
ЁЁЁЁЕЭЗхЪБЖЮВњЩњШБЪЇЪ§ОнЧщПіЃЌИљОнЧАжмЦкгыжмБпТЗПіХаЖЈЪЧСїСПЙ§ЕЭЕМжТаЁбљБОЕФЧщПіЃЌвдЕРТЗздгЩСїЫйЯТЖдгІЕФТУааЪБМфзїЮЊВЙГЅНсЙћЁЃ
ЁЁЁЁ3.5 НЛЭЈзДПіЭЦЫу
ЁЁЁЁНЛЭЈгЕЖТЕШМЖХаБ№ОЭЪЧИљОнЕБЧАЕФНЛЭЈСїЬиеїаХЯЂЃЌНсКЯНЛЭЈжЊЪЖНЋНЛЭЈгЕМЗГЬЖШНјааЕШМЖЛЎЗжЃЌвдСПЕФаЮЪНЗЂВМЕБЧАЕФНЛЭЈгЕЖТаХЯЂЁЃТЗЖЮЕФааГЬЫйЖШЪЧБэеїНЛЭЈгЕМЗзДЬЌЕФвЛИіжБЙлЁЂгааЇЕФНЛЭЈСїВЮЪ§ЁЃгЩгкНЛЭЈгЕМЗЕФБОжЪЪЧГЕСОЕФЪЕМЪааГЬЫйЖШЕЭгкШЫУЧЦкЭћЕФааГЬЫйЖШЃЌвђДЫЃЌдкФмЙЛПЩППЕиЛёЕУНЛЭЈСїЦНОљааГЬЫйЖШЪ§ОнЕФЧщПіЯТЃЌЭЈЙ§НЋЦфгыдЄЖЉЕФЦкЭћааГЬЫйЖШНјааБШНЯЃЌПЩвдЪЕЯжЖдЕРТЗНЛЭЈзДЬЌЕФЪЖБ№ЁЃ
ЁЁЁЁПЩвдНЋГЕСОдкФГЬѕЕРТЗЕФЦНОљааГЬЫйЖШзїЮЊХаЖЯИУЕРТЗгЕЖТзДПіЕФвЛИіВЮЪ§ЁЃвбжЊЭГМЦТЗЖЮБОжмЦкТУааЪБМфЮЊT1ЃЌЛЛЫуИУТЗЖЮЕФЦНОљааГЬЫйЖШЮЊЃК

ЁЁЁЁИљОнЙњФкЭтЕФЪЕМљОбщЃЌГЧЪаЕРТЗНЛЭЈзДЬЌЕФЛЎЗжвРОнжївЊВЮЪ§гІИУЪЧТЗЖЮЕФЦНОљааГЬЫйЖШЁЃЛљгкетвЛПМТЧЃЌвРОнГЧЪаЕРТЗЕШМЖМАНЛЭЈзДЬЌЛЎЗжЕФСйНчЫйЖШжЕНЋГЧЪаЕРТЗНЛЭЈзДЬЌЛЎЗжЮЊГЉЭЈЁЂЛљБОГЉЭЈЁЂгЕМЗЁЂгЕЖТЁЂЖТШћЕШ5ИіЕШМЖЃЌШчБэ1ЫљЪОЁЃ
ЁЁЁЁБэ1 ГЧЪаЕРТЗНЛЭЈзДЬЌМЖБ№ЛЎЗжвРОн
|
Зж Рр ЕШ МЖ |
A |
B |
C |
D |
E |
|
|
ФЃК§УшЪі |
ГЉЭЈ |
ЛљБОГЉЭЈ |
гЕМЗ |
гЕЖТ |
ЖТШћ |
|
|
ЦНОљааГЬЫйЖШЃЈkm/hЃЉ |
ПьЫйТЗ |
>60 |
[40,60] |
[30,40] |
[20,30] |
<20 |
|
жїИЩТЗ |
>45 |
[35,45] |
[25,35] |
[15,25] |
<15 |
|
|
ДЮИЩТЗ |
>35 |
[25,35] |
[18,25] |
[12,18] |
<12 |
|
|
жЇТЗ |
>25 |
[18,25] |
[12,18] |
[8,12] |
<8 |
|
ЁЁЁЁ4 ЪЕВтЪ§ОнбщжЄ
ЁЁЁЁЮЊСЫбщжЄЗНЗЈЕФгааЇадЃЌБОЮФВЩгУГЄТЗЖЮТУааЪБМфМЦЫуЕФзМШЗадЖдЗНЗЈНјааВтЪдЁЃбЁШЁВтЪдЕФТЗЖЮЮЛгкФГЪа700УзГЄТЗЖЮЃЌШЋГЬЗтБеУЛгаЦфЫћГіШыПкЃЌВЩМЏЕФбљБОЮЊЩЯгЮжБааКЭзѓзЊНјШыТЗЖЮЕФГЕСОЁЃ
ЁЁЁЁ4.1 ЭГМЦШЋЬьЙ§ГЕЧщПі
ЁЁЁЁЃЈ1ЃЉЩЯгЮТЗПквЛЬьЕФЙ§ГЕСПОљжЕЮЊ 45844СОЃЌЦфжааЁаЭГЕЮЊ15132СОЃЌдМеМзмЪ§ЕФ33%ЁЃ
ЁЁЁЁЃЈ2ЃЉЯТгЮТЗПквЛЬьЕФЙ§ГЕСПОљжЕ17415СОЃЌЦфжааЁаЭГЕЮЊ10462СОЃЌдМеМзмЪ§ЕФ60%ЁЃ
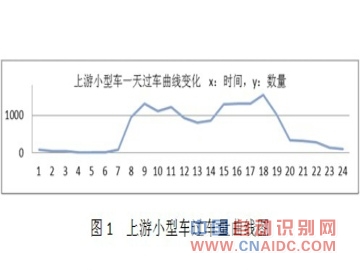
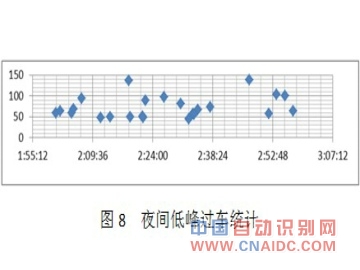
ЁЁЁЁЃЈ3ЃЉШЋЬьУП5ЗжжгЃЌЩЯгЮГЕХЦКЭЯТгЮГЕХЦЦЅХфЕФаЁаЭГЕЪ§СПЭГМЦНсЙћШчЭМ3ЫљЪОЁЃ
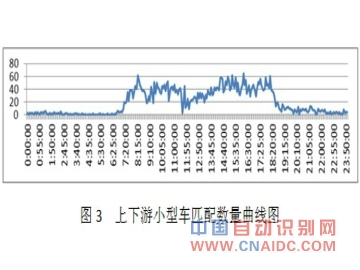
ЁЁЁЁЃЈ4ЃЉШЋЬьЦЅХфГЕСОЕФТУааЪБМфЭГМЦНсЙћШчЭМ4ЫљЪОЁЃ
ЁЁЁЁЗЧгЕЖТЧщПіЯТЃЌДцдкВПЗжГЕСОЕФТУааЪБМфДѓгк500sЃЌОЕїВщЗжЮідвђШчЯТЃКГЕСОдкЯТгЮТЗПкЕчзгОЏВьЧАЕєЭЗЃЌШЅЖдУцГЕЕРЯТгЮДІМггЭЃЌШЛКѓдйЕїзЊГЕЭЗЛиЕНЯТгЮТЗПкЁЃЕМжТТУааЪБМфБШЭЌжмЦкЕФЖрГі5ЗжжгЁЃЪЕМЪЧщПіШчЭМ5ЫљЪОЃК

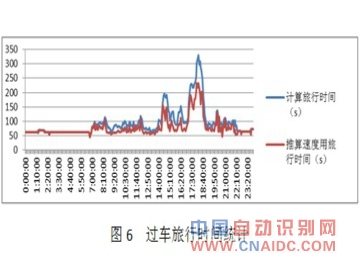
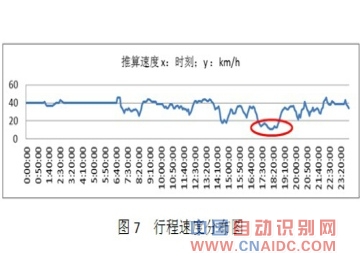
ЁЁЁЁЃЈ5ЃЉЙ§ГЕТУааЪБМфКЭааГЬЫйЖШЗжВМШчЭМ6КЭЭМ7ЫљЪОЃК
ЁЁЁЁЃЈ1ЃЉвЙМфЕЭЗхЪБЖЮ02ЃК00 ЁЋ 03ЃК00
ЁЁЁЁЃЈ2ЃЉдчИпЗхЪБЖЮ07ЃК00 ЁЋ 09ЃК00
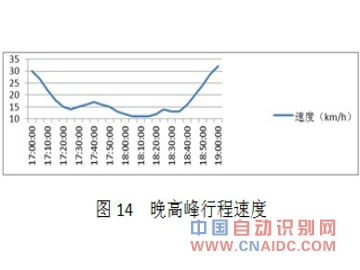
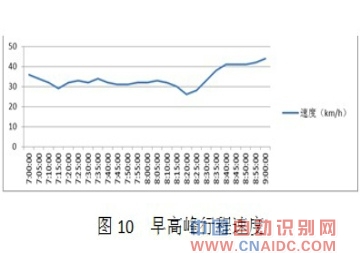
ЁЁЁЁЦНЗхЪБЖЮЃЌГЕСОЪмаХКХЕЦЕФгАЯьЃЌТУааЪБМфЕФЗЂВМУїЯдГЪЯжЗжСНВуаЮЬЌЁЃМЦЫуЕФТУааЪБМфОИХТЪЭГМЦКѓЃЌШЁжаМфжЕЗЂВМЁЃ
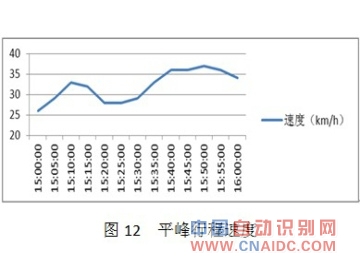
ЁЁЁЁБэ2 ЦНЗхЦНОљЦНЗНЮѓВю
|
ЪБ Мф ЖЮ |
RMSPE |
ЪБ Мф ЖЮ |
RMSPE |
|
15:00:00 |
5.66% |
15:35:00 |
9.50% |
|
15:05:00 |
6.55% |
15:40:00 |
10.61% |
|
15:10:00 |
13.64% |
15:45:00 |
12.10% |
|
15:15:00 |
4.30% |
15:50:00 |
14.86% |
|
15:20:00 |
1.70% |
15:55:00 |
12.29% |
|
15:25:00 |
11.24% |
16:00:00 |
3.44% |
|
15:30:00 |
3.67% |
ЦНОљ |
8.43% |
ЁЁЁЁЃЈ4ЃЉЭэИпЗхЪБЖЮ17ЃК00 ЁЋ19ЃК00
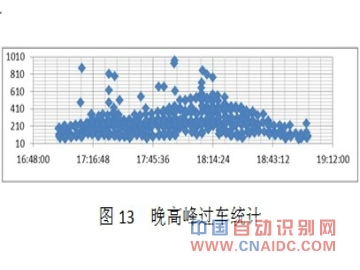
ЁЁЁЁБэ3 ЭэИпЗхЦНОљЦНЗНЮѓВю
|
ЪБМфЖЮ |
RMSPE |
ЪБМфЖЮ |
RMSPE |
|
17:00:00 |
5.77% |
18:05:00 |
14.38% |
|
17:05:00 |
0.39% |
18:10:00 |
9.77% |
|
17:10:00 |
3.51% |
18:15:00 |
12.28% |
|
17:15:00 |
1.77% |
18:20:00 |
20.56% |
|
17:20:00 |
14.03% |
18:25:00 |
11.64% |
|
17:25:00 |
8.94% |
18:30:00 |
6.51% |
|
17:30:00 |
5.13% |
18:35:00 |
4.46% |
|
17:35:00 |
5.23% |
18:40:00 |
5.55% |
|
17:40:00 |
13.68% |
18:45:00 |
10.11% |
|
17:45:00 |
10.50% |
18:50:00 |
12.71% |
|
17:50:00 |
9.13% |
18:55:00 |
17.01% |
|
17:55:00 |
14.64% |
19:00:00 |
4.22% |
|
18:00:00 |
17.97% |
ЁЁЦНОљ |
9.59% |
ЁЁЁЁДгЗНЗЈВтЪдНсЙћПЩМћЃЌТУааЪБМфдкИїЪБМфЖЮЕФЦНОљЦНЗНЮѓВюНЯаЁЃЌВЂЧвМЦЫуНсЙћгыЪЕМЪНЛЭЈЧщПіЯрЗћЃЌБэУїИУЗНЗЈНЛЭЈзДЬЌХаБ№ЕФгааЇадЁЃ
ЁЁЁЁ5 Нсгя
ЁЁЁЁБОЮФЩшМЦСЫвЛжжЛљгкГЕХЦЪЖБ№Ъ§ОнЕФТУааЪБМфВЩМЏМАДІРэЗНЗЈЖдНЛЭЈзДЬЌНјааХаБ№ЁЃЭЈЙ§вьГЃЪ§ОнЬоГ§ЁЂШБЪЇЪ§ОнВЙГЅЕШЪ§ОнДІРэКЭбљБОСПМАНЛЭЈЪБЖЮЕФЛЎЗжЃЌБЃжЄСЫТУааЪБМфМЦЫуЕФзМШЗадКЭКЯРэадЁЃЪ§ОнВтЪдНсЙћБэУїЃЌЗНЗЈВЛЕЋПЩвдзМШЗМЦЫуГіТУааЪБМфКЭЕРТЗзДЬЌЃЌЭЌЪБЛЙПЩвдИјГіТЗЖЮЕФЭэЕЭЗхЁЂдчИпЗхЁЂЦНЗхЪБЖЮЁЂвЙМфЕЭЗхЕФЦ№жЙЪБМфКЭЦНОљГЕЫйЕШаХЯЂЃЌФмЙЛЮЊНЛЭЈЙмжЦЬсЙЉгааЇЕФОіВпвРОнЁЃ
![ЕМКНЙІФмКѓЪгОЕ:жаЙњЕчаХЭЦПЩЕМКНЕФЁАжЧФмГЕдиКѓЪгОЕЁБ[ЭМ]](http://www.cnaidc.com/file/upload/201311/20/20-08-35-88-1.jpg)




